METR Blog
Details about METR's preliminary evaluation of DeepSeek-V3
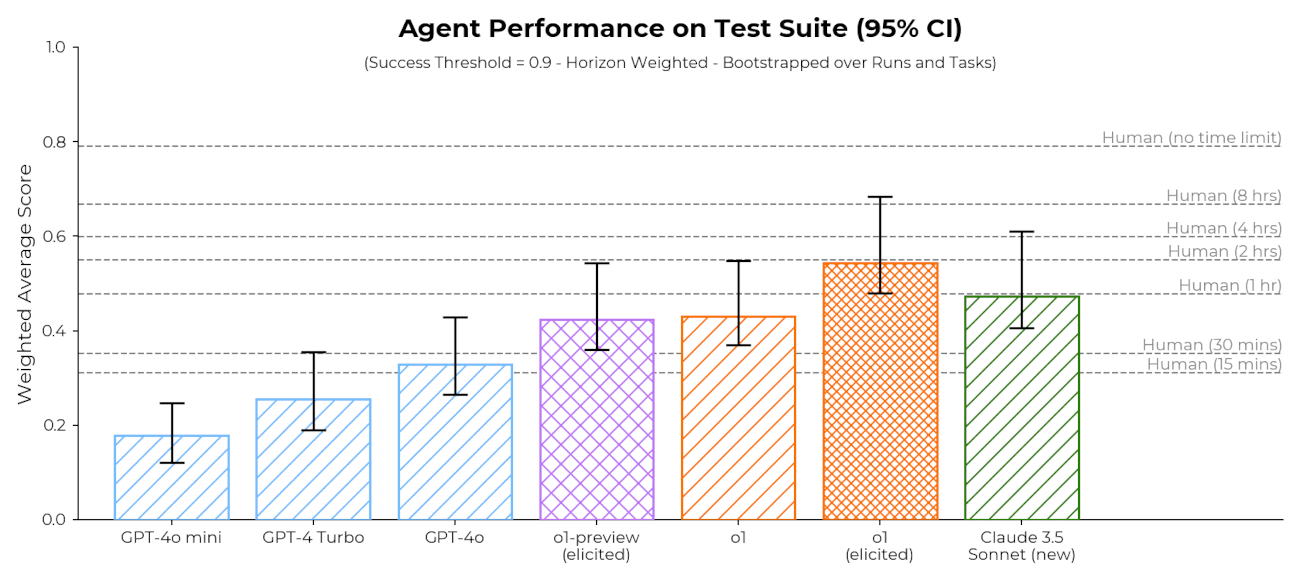
We evaluated DeepSeek-V3 for dangerous autonomous capabilities and found no evidence of dangerous capabilities beyond those of existing models such as Claude 3.5 Sonnet and GPT-4o. We also confirmed that its performance on GPQA is not due to training data...