METR Blog
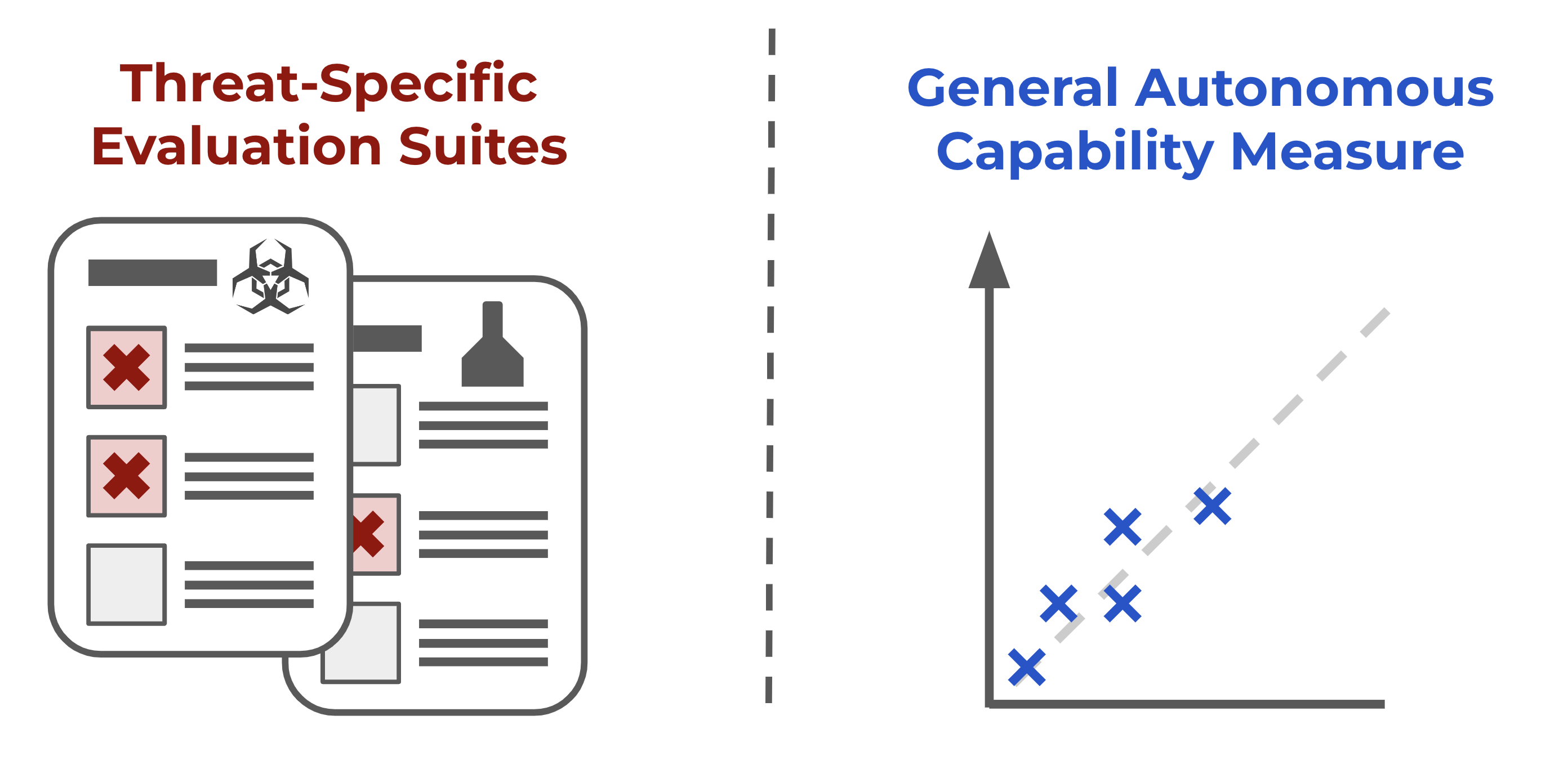
An update on our general capability evaluations
More tasks, human baselines, and preliminary results for GPT-4 and Claude.
METR Blog
More tasks, human baselines, and preliminary results for GPT-4 and Claude.
METR Blog
Comments on NIST’s draft document “AI Risk Management Framework: Generative AI Profile.”
METR Blog
METR is hiring ML engineers and researchers.
METR Blog
Emma moves from President to Executive Director, Beth moves to Head of Research.
METR Blog
A collection of resources for evaluating potentially dangerous autonomous capabilities of frontier models.
METR Blog
An example protocol for the whole evaluation process, based on our task suite, elicitation protocol, and scoring methods.
METR Blog
Contribute to METR/public-tasks development by creating an account on GitHub.
METR Blog
Priorities for approximating the full potential capability of an AI agent, and recommended checks for evaluation validity.
METR Blog
A brief research report outlining quantitative research which could inform the "safety margin" to add to take into account further post-training enhancements to agent capability.
METR Blog
METR has published a standard way to define tasks for evaluating the capabilities of AI agents.
METR Blog
A summary of what METR accomplished in 2023 – our first full year of operation.
METR Blog
METR (formerly ARC Evals) is looking for (1) ideas, (2) detailed specifications, and (3) well-tested implementations for tasks to measure performance of autonomous LLM agents.