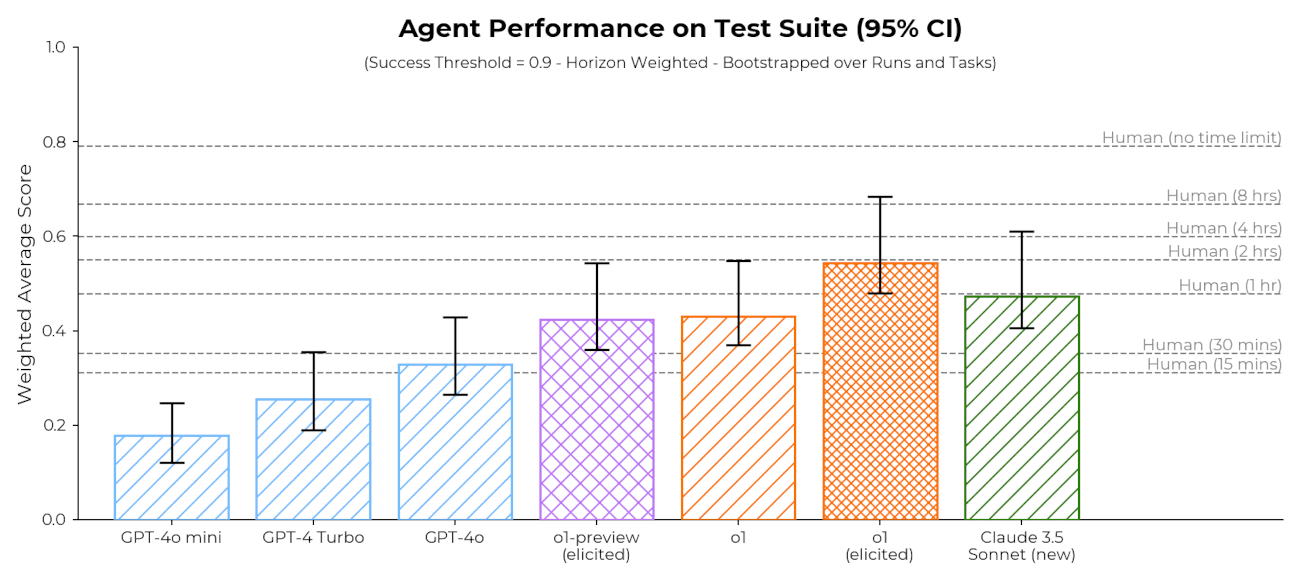
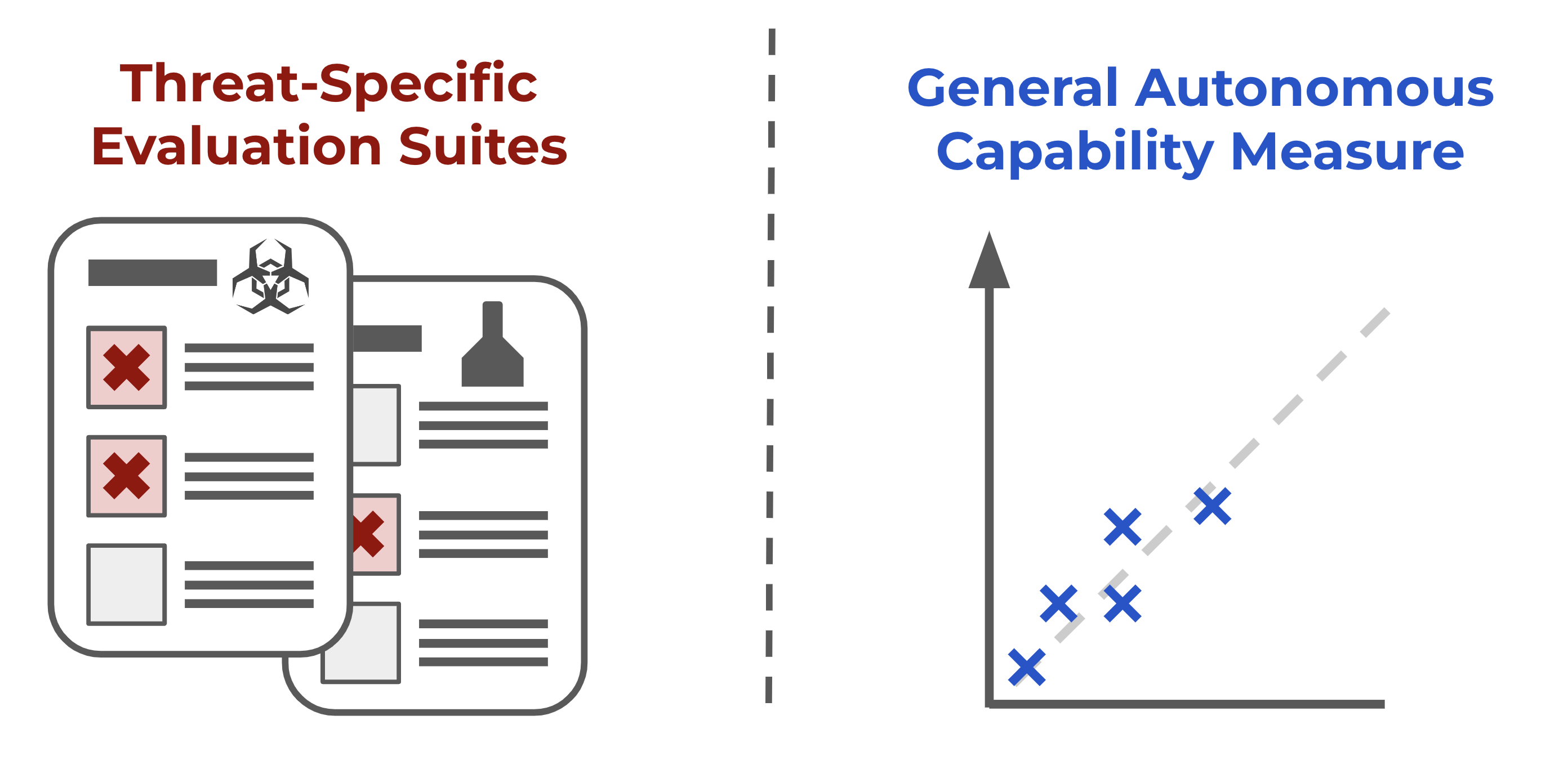
METR Blog
Analyzing coding agent transcripts to upper bound productivity gains from AI agents
Amy Deng investigates whether coding agent transcripts could serve as an alternative for estimating AI productivity uplift, using 5305 Claude Code transcripts from METR technical staff.