Google News AI Safety Evaluation
+ 1 source
Claude Mythos Shows 50% Time Horizon Of 16+ Hours On METR Benchmark - OfficeChai
Claude Mythos Shows 50% Time Horizon Of 16+ Hours On METR Benchmark OfficeChai
Concept
Google News AI Safety Evaluation
+ 1 source
Claude Mythos Shows 50% Time Horizon Of 16+ Hours On METR Benchmark OfficeChai
Google News SWE Bench
Scale Labs debuts new Refactoring Leaderboard for AI TestingCatalog AI News
Google News MLPerf
Cisco and AMD Benchmark Scale-out AI Fabric Performance Let's Data Science
MLCommons Evaluation Filter
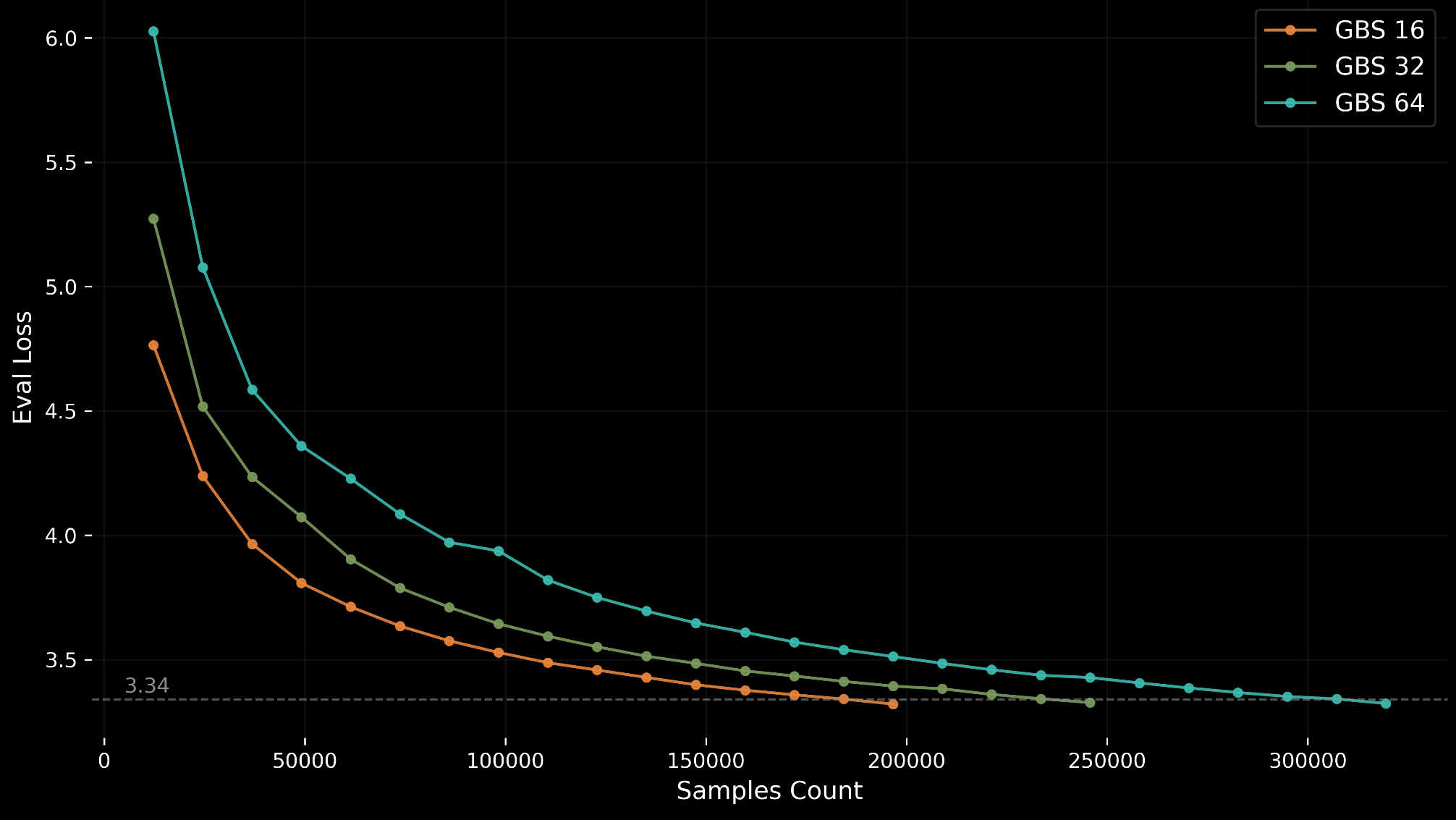
MLPerf Training v6.0 introduces GPT-OSS 20B, a new sparse Mixture-of-Experts (MoE) pretraining benchmark designed for accessibility on single 8-GPU nodes.
Google News AI Benchmarks
+ 1 source
DeepSeek V4 analysis: What's the point of topping the AI leaderboard if nobody can afford you? news.cgtn.com
Google News Eval Frameworks
Claude Opus 4.7, Gemini 3.1 Pro, and Others Score 0% on New SWE Benchmark Analytics India Magazine

Hugging Face Evaluation Filter
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
MLCommons Evaluation Filter
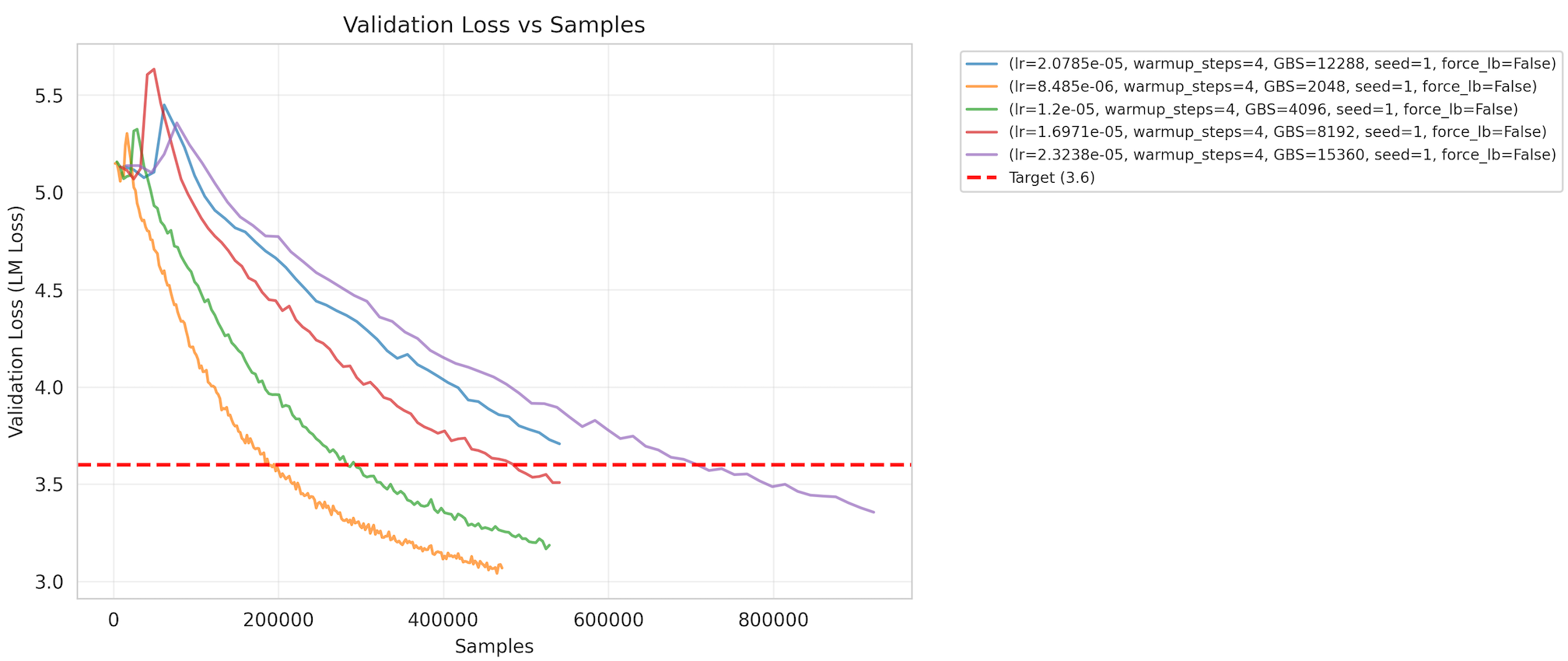
MLPerf Training v6.0 introduces a large-scale pretraining benchmark built on DeepSeek-V3, bringing Mixture-of-Experts (MoE) evaluation to the suite.
Google News LLM Evaluation
Alphabet just became the Magnificent 7's new AI benchmark Opening Bell Daily

Hugging Face Evaluation Filter
A Blog post by Technology Innovation Institute on Hugging Face

MLCommons Evaluation Filter
MLCommons introduces Continuous Prompt Stewardship to keep the AILuminate AI safety benchmark fresh and reliable as frontier models evolve.
Google News LLM Evaluation
EQS AI Benchmark Report Vol. 2 EQS Group