METR Blog
Review of the Anthropic Summer 2025 Pilot Sabotage Risk Report
External review from METR of Anthropic's Summer 2025 Sabotage Risk Report
METR Blog
External review from METR of Anthropic's Summer 2025 Sabotage Risk Report
METR Blog
Details on external recommendations from METR for gpt-oss Preparedness experiments and follow-up from OpenAI.
METR Blog
MALT (Manually-reviewed Agentic Labeled Transcripts) is a dataset of natural and prompted examples of behaviors that threaten evaluation integrity (like generalized reward hacking or sandbagging).
METR Blog
Vincent Cheng, Thomas Kwa, and Neev Parikh share research on how AI agents can hide secondary task-solving from monitors, finding that harder tasks are more detectable and small models can learn to evade larger monitors.
METR Blog
Vincent Cheng and Thomas Kwa replicate a Google DeepMind paper on chain-of-thought monitoring, showing evidence that monitoring works on other companies' models.
METR Blog
AI agents are improving rapidly at autonomous software development and machine learning tasks, and, if recent trends hold, may match human researchers at challenging months-long research projects in under a decade. Some economic models predict that...
METR Blog
Many AI benchmarks use algorithmic scoring to evaluate how well AI systems perform on some set of tasks. However, AI systems often produce code that scores well but isn't production-ready due to issues with test coverage, formatting, and code quality. This...
METR Blog
How we think about tradeoffs when communicating surprising or nuanced findings.
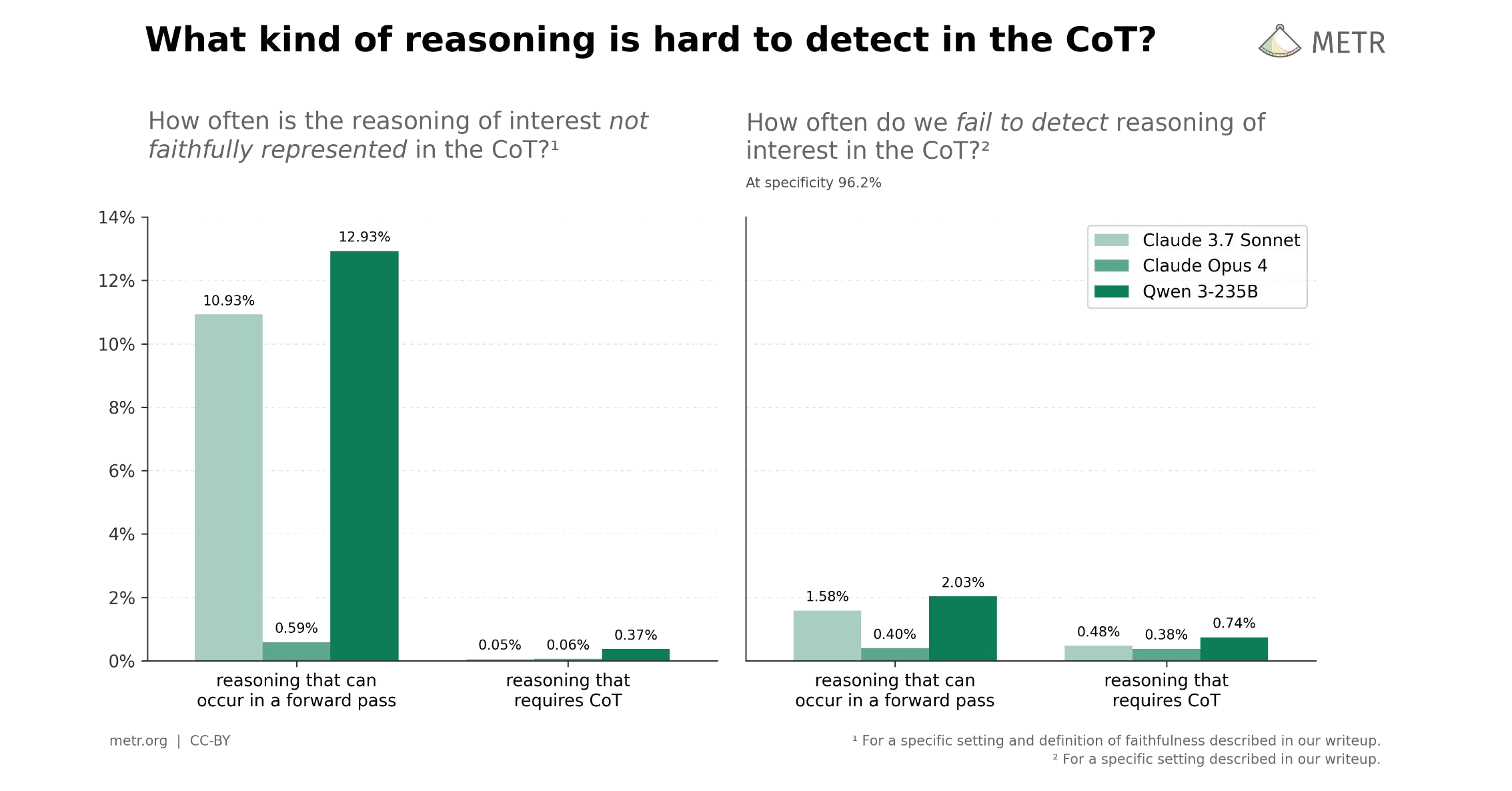
METR Blog
Recent work from Anthropic and others claims that LLMs' chains of thoughts can be “unfaithful”. These papers make an important point: you can't take everything in the CoT at face value. As a result, people often use these results to conclude the CoT is...
METR Blog
We evaluate whether GPT-5 poses significant catastrophic risks via AI self-improvement, rogue replication, or sabotage of AI labs. We conclude that this seems unlikely. However, capability trends continue rapidly, and models display increasing eval awareness.
METR Blog
We build on our time-horizon work and analyze 9 benchmarks for scientific reasoning, math, robotics, computer use, and self-driving in terms of time-horizon trends; we observe generally similar rates of improvement to the 7-month doubling time in our...
METR Blog
We conduct a randomized controlled trial to understand how early-2025 AI tools affect the productivity of experienced open-source developers working on their own repositories. Surprisingly, we find that when developers use AI tools, they take 19% longer...