METR Blog
Evaluating frontier AI R&D capabilities of language model agents against human experts
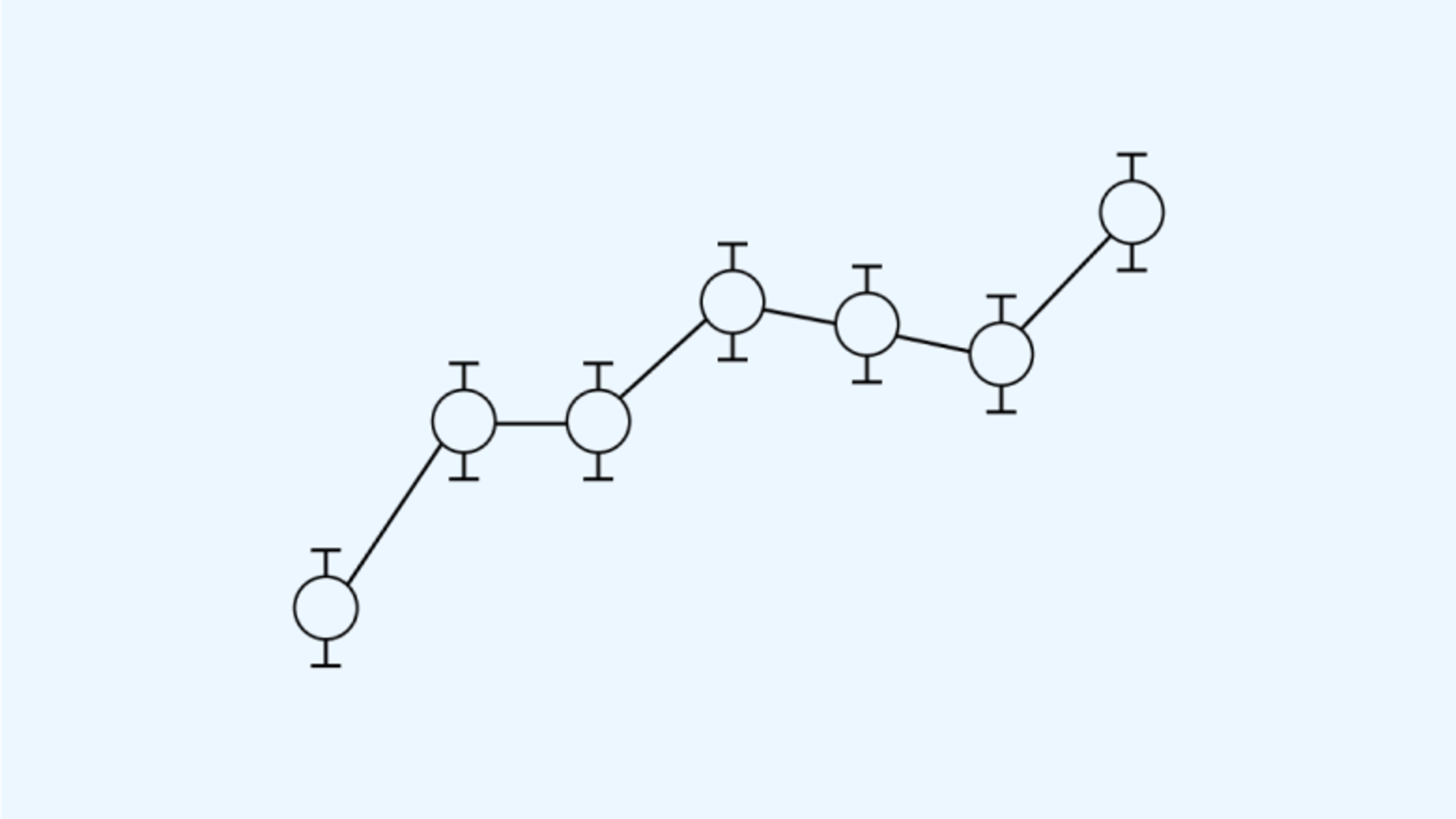
We’re releasing RE-Bench, a new benchmark for measuring the performance of humans and frontier model agents on ML research engineering tasks. We also share data from 71 human expert attempts and results for Anthropic’s Claude 3.5 Sonnet and OpenAI’s...