
Hugging Face Evaluation Filter
The Open Arabic LLM Leaderboard 2
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Community feed
A focused stream of recent stories from the sources curated for this community. Latest: The Open Arabic LLM Leaderboard 2, Frontier AI Safety Policies, and DABStep: Data Agent Benchmark for Multi-step Reasoning. Page 28.
Hugging Face Evaluation Filter
We’re on a journey to advance and democratize artificial intelligence through open source and open science.

Hugging Face Evaluation Filter
We’re on a journey to advance and democratize artificial intelligence through open source and open science.

OpenAI Evaluation Filter
This report outlines the safety work carried out for the OpenAI o3-mini model, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
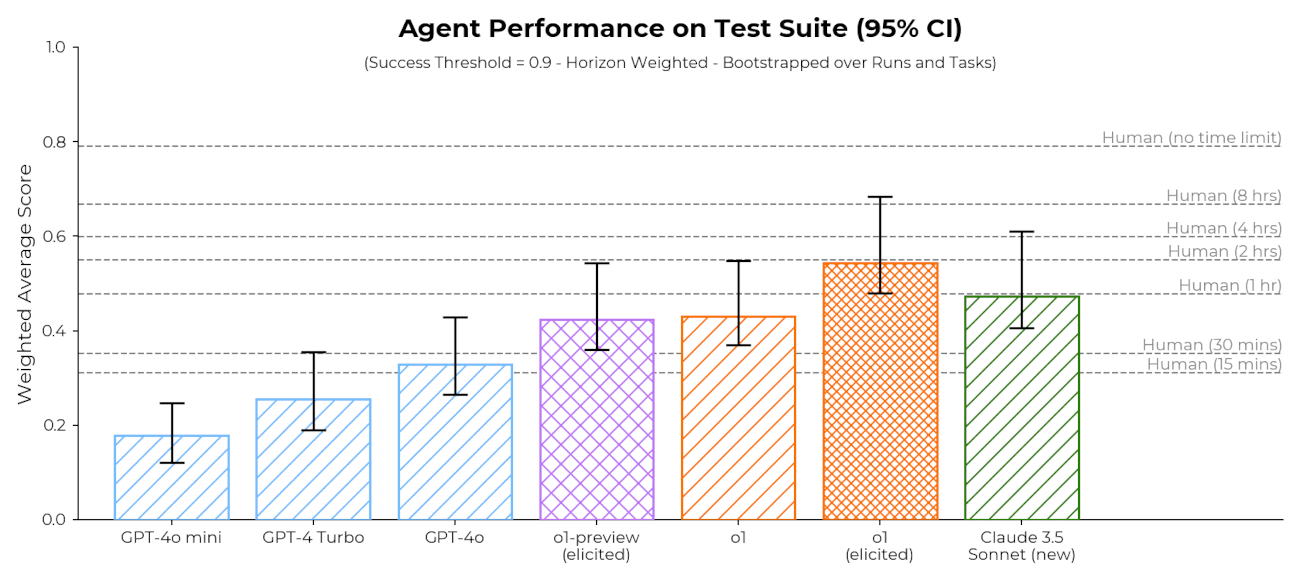
METR Blog
Preliminary evaluations of Claude 3.5 Sonnet (New) and o1, as well as some discussion of challenges in making capability-based safety arguments for AI models.
Google News LLM Evaluation
Track LLM model evaluation using Amazon SageMaker managed MLflow and FMEval | Amazon Web Services Amazon Web Services (AWS)

OpenAI Evaluation Filter
Drawing from OpenAI’s established safety frameworks, this document highlights our multi-layered approach, including model and product mitigations we’ve implemented to protect against prompt engineering and jailbreaks, protect privacy and security, as well...
METR Blog
Why pre-deployment testing is not an adequate framework for AI risk management

Hugging Face Evaluation Filter
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Google News LLM Evaluation
What Makes a Good AI Benchmark? Stanford HAI

OpenAI Evaluation Filter
This report outlines the safety work carried out prior to releasing OpenAI o1 and o1-mini, including external red teaming and frontier risk evaluations according to our Preparedness Framework.

Hugging Face Evaluation Filter
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
More stories load automatically as you scroll.