METR Blog
Review of the Anthropic Summer 2025 Pilot Sabotage Risk Report
External review from METR of Anthropic's Summer 2025 Sabotage Risk Report
Company
METR Blog
External review from METR of Anthropic's Summer 2025 Sabotage Risk Report

OpenAI Evaluation Filter
OpenAI and Anthropic share findings from a first-of-its-kind joint safety evaluation, testing each other’s models for misalignment, instruction following, hallucinations, jailbreaking, and more—highlighting progress, challenges, and the value of cross-lab...
METR Blog
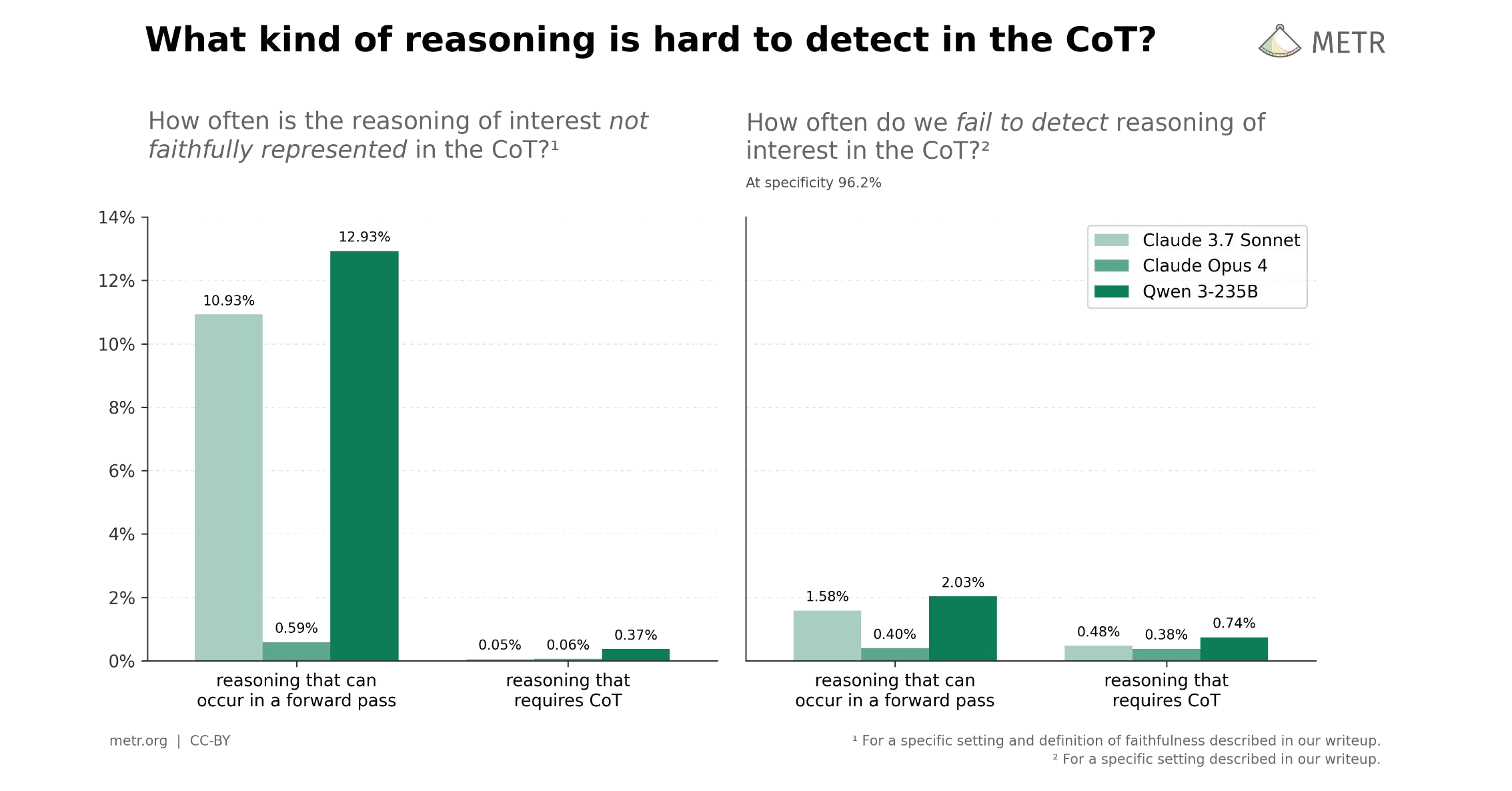
Recent work from Anthropic and others claims that LLMs' chains of thoughts can be “unfaithful”. These papers make an important point: you can't take everything in the CoT at face value. As a result, people often use these results to conclude the CoT is...
METR Blog
We’re releasing RE-Bench, a new benchmark for measuring the performance of humans and frontier model agents on ML research engineering tasks. We also share data from 71 human expert attempts and results for Anthropic’s Claude 3.5 Sonnet and OpenAI’s...