MLCommons Evaluation Filter
GPT-OSS 20B: A Sparse MoE Pretraining Benchmark for MLPerf Training v6.0 - MLCommons
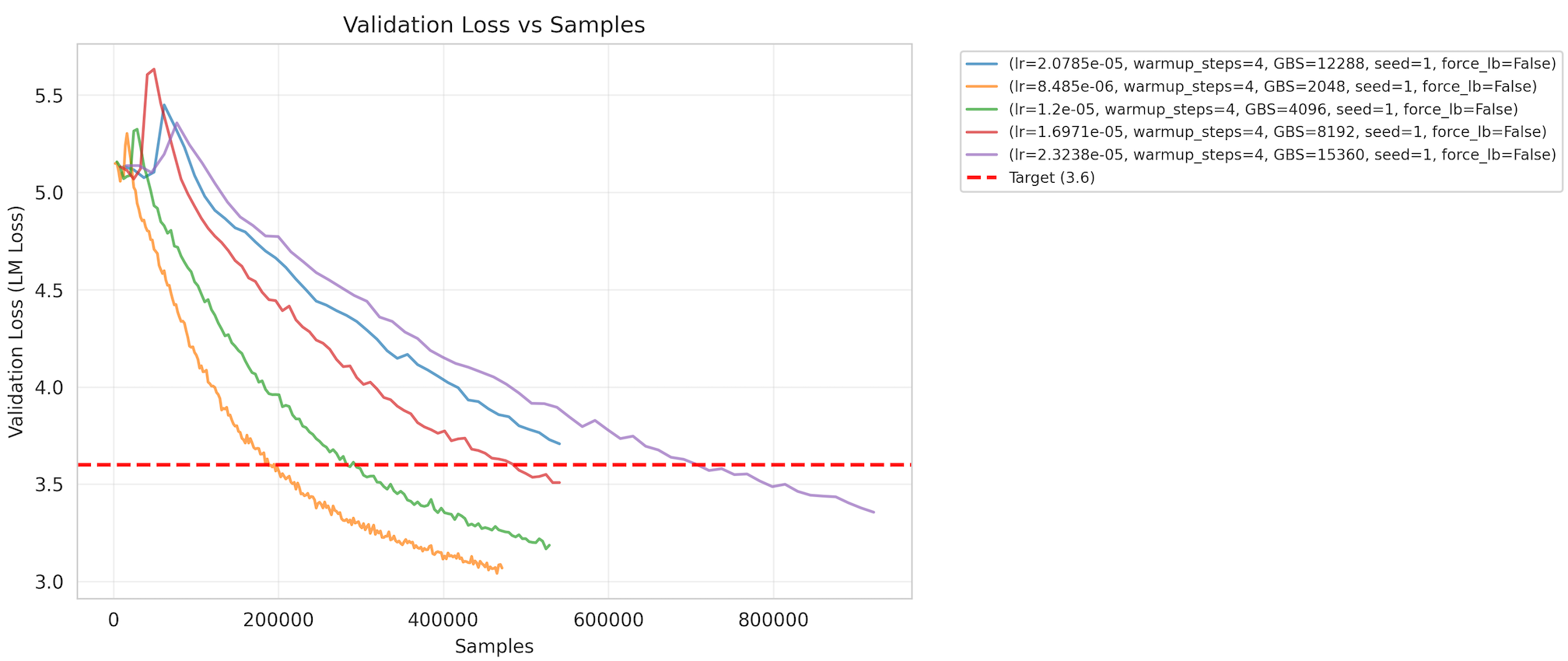
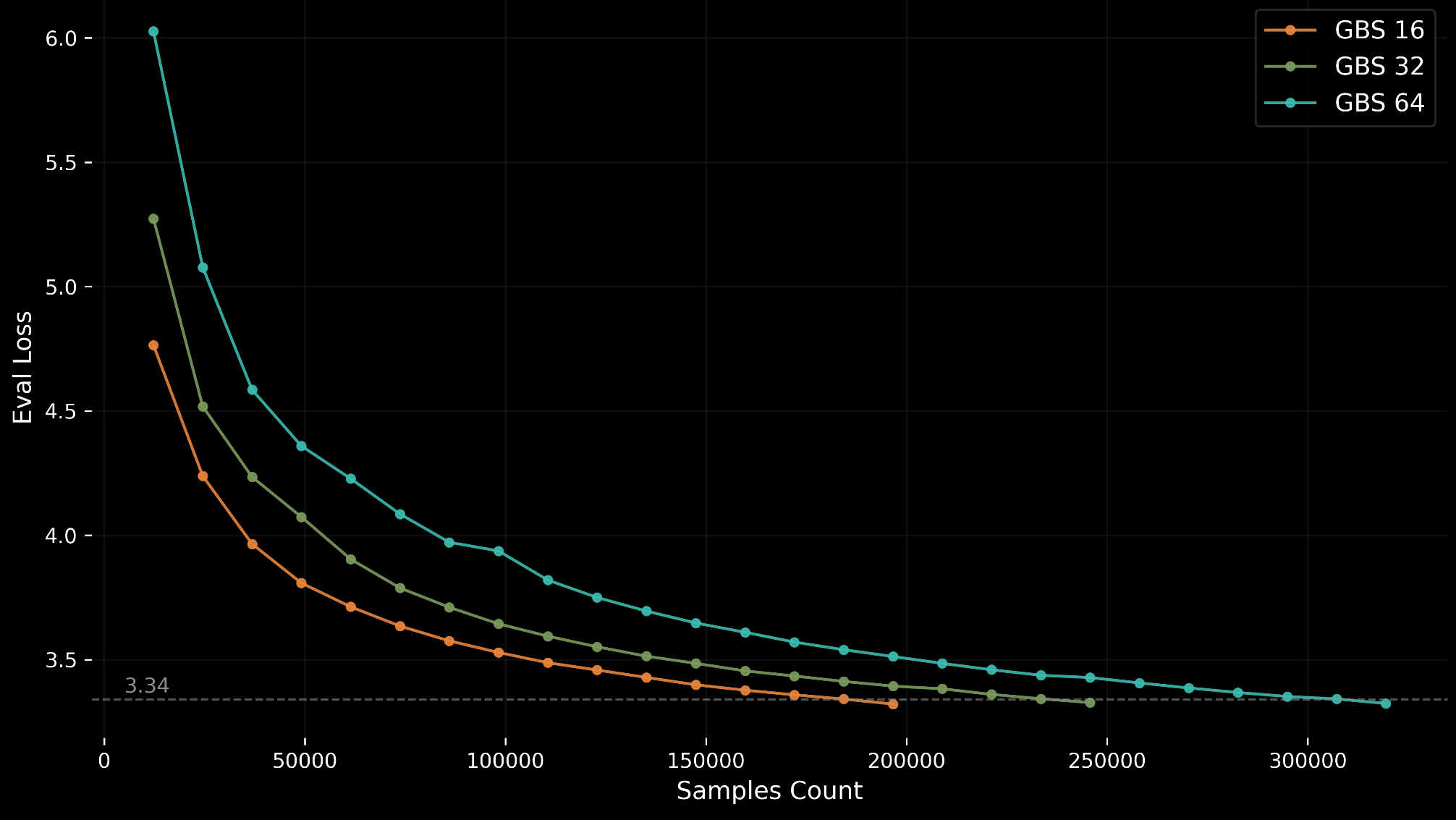
MLPerf Training v6.0 introduces GPT-OSS 20B, a new sparse Mixture-of-Experts (MoE) pretraining benchmark designed for accessibility on single 8-GPU nodes.