Hacker News LLM Evaluation
Build software better, together
GitHub is where people build software. More than 150 million people use GitHub to discover, fork, and contribute to over 420 million projects.
Hacker News LLM Evaluation
GitHub is where people build software. More than 150 million people use GitHub to discover, fork, and contribute to over 420 million projects.
Hacker News LLM Evaluation
I have been reading a ton about LLM evaluation practices over the past few weeks from Anthropic’s engineering blog, Hamel Husain’s practitioner-focused guides, the Evals for AI Engineers book by Shreya Shankar and Hamel Husain, and several eval framework...

Hacker News LLM Evaluation
In this article, I'll walkthrough everything you need to know about LLM evaluation metrics, with code samples.
Hacker News LLM Evaluation
Compare LLM models side by side with 3 lines of Python. Track evaluations across GPT, Claude, Llama and any model. Radar charts, scorecards, real-time streaming. Free forever.
Hacker News LLM Evaluation
Polyglot ontological activations for LLM systems. 68 terms from 20+ traditions mapped to computational patterns, plus 10 algorithms native to the ontology that have no equivalents in standard CS. Includes benchmark suite and a documented evaluation...
Hacker News LLM Evaluation
Evaluation Framework for LLM applications in Java and Kotlin - dokimos-dev/dokimos

Hacker News LLM Evaluation
Explore best practices for building an evaluation framework for production LLM applications.
Hacker News LLM Evaluation
Spark-native LLM evaluation framework with confidence intervals, significance testing, and Databricks integration - bassrehab/spark-llm-eval
Hacker News LLM Evaluation
smallevals — CPU-fast, GPU-blazing fast offline retrieval evaluation for RAG systems with tiny QA models. - mburaksayici/smallevals

Hacker News LLM Evaluation
This page automatically loads score data from several LLM leaderboards and shows an interactive chart that tracks how top benchmark results have changed. The chart groups benchmarks by category, hi...
Hacker News LLM Evaluation
Abstract page for arXiv paper 2511.06346: LPFQA: A Long-Tail Professional Forum-based Benchmark for LLM Evaluation
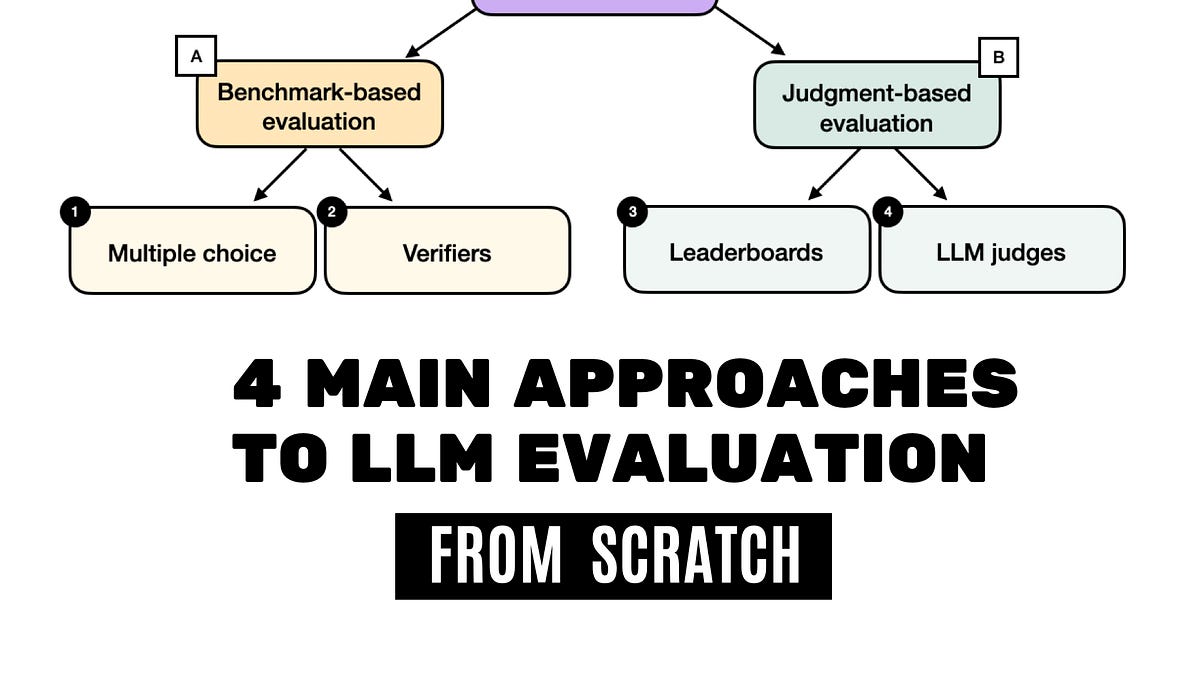
Hacker News LLM Evaluation
Multiple-Choice Benchmarks, Verifiers, Leaderboards, and LLM Judges with Code Examples