
Hugging Face Evaluation Filter
Adding Benchmaxxer Repellant to the Open ASR Leaderboard
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Community feed
A focused stream of recent stories from the sources curated for this community. Latest: Adding Benchmaxxer Repellant to the Open ASR Leaderboard, Google DeepMind, Microsoft and xAI Sign Agreements for US National Security AI Testing - Technobezz, and Studying AI’s reliability for pregnancy medication questions, with Erick Holder, MD - Contemporary OB/GYN. Page 7.
Hugging Face Evaluation Filter
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Google News AI Testing
Google DeepMind, Microsoft and xAI Sign Agreements for US National Security AI Testing Technobezz
Google News AI Testing
Studying AI’s reliability for pregnancy medication questions, with Erick Holder, MD Contemporary OB/GYN
Google News AI Testing
Microsoft : signs new deals with US and UK partners to advance AI testing and safety marketscreener.com
Google News AI Red Teaming
Youth AI Safety Independent Testing Regime Launch - Hold Rating newser.com
Google News AI Red Teaming
Youth AI Safety Independent Testing Regime Launch - Hot Community Stocks newser.com
Google News Frontier AI Testing
+ 1 source
Microsoft signs AI testing agreement with UK's security institute The Economic Times
Google News AI Testing
Advancing AI evaluation with the Center for AI Standards (US) and Innovation and the AI Security Institute (UK) The Official Microsoft Blog
Google News Frontier AI Testing
+ 1 source
Microsoft Signs AI Testing Agreement With Uk's AI Security Institute - Company Statement TradingView
Google News AI Testing
TestSprite: Interview With Co-Founder & CEO Yunhao Jiao About The Autonomous AI Testing Agent Pulse 2.0
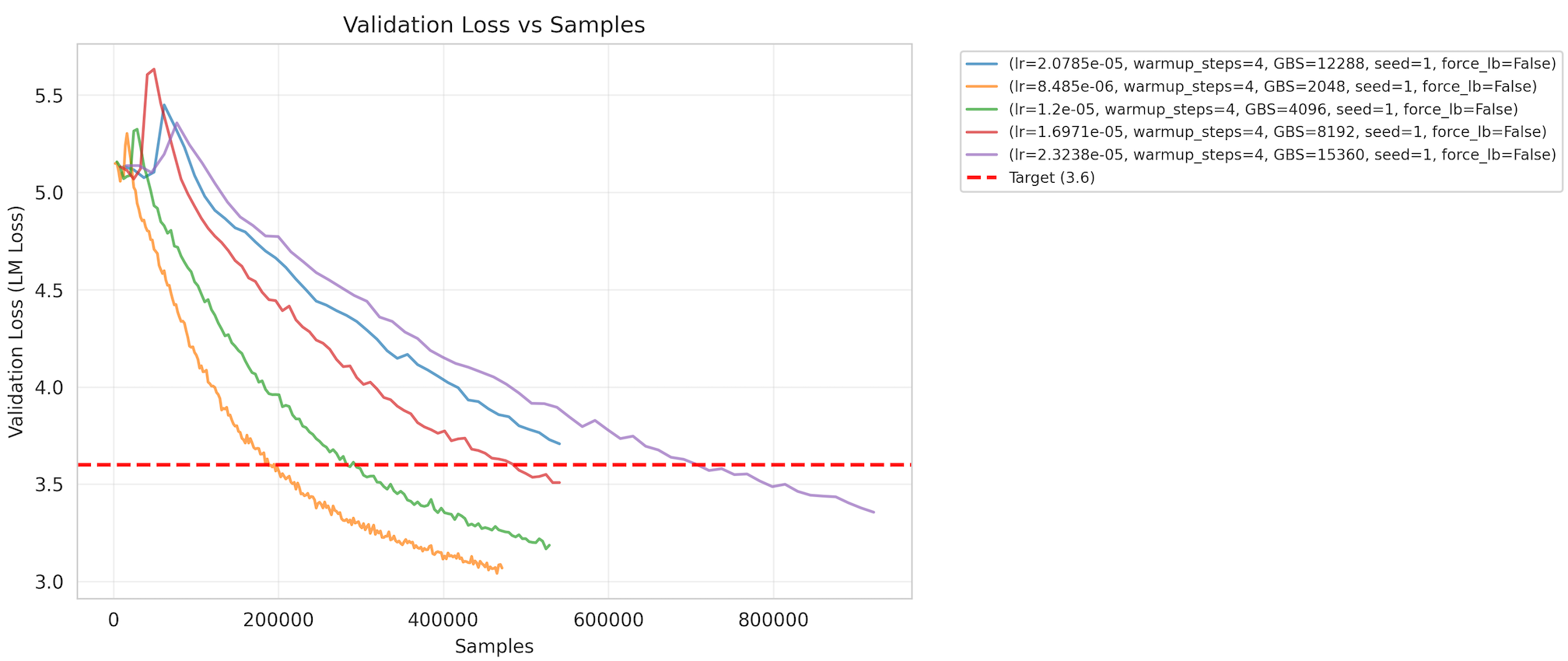
MLCommons Evaluation Filter
MLPerf Training v6.0 introduces a large-scale pretraining benchmark built on DeepSeek-V3, bringing Mixture-of-Experts (MoE) evaluation to the suite.
Google News AI Testing
UAE launches national AI testing lab to certify models and agents crypto.news
More stories load automatically as you scroll.