Google News AI Testing
Amazon's battle to block Perplexity AI testing reach of computer-access laws - MLex
Amazon's battle to block Perplexity AI testing reach of computer-access laws MLex
Community feed
A focused stream of recent stories from the sources curated for this community. Latest: Amazon's battle to block Perplexity AI testing reach of computer-access laws - MLex, US government AI testing underway - Tech giants to evaluate models - Scan TV, and Collate Emphasizes Semantic Data Layer as Key to Enterprise AI Reliability - TipRanks. Page 5.
Google News AI Testing
Amazon's battle to block Perplexity AI testing reach of computer-access laws MLex
Google News AI Testing
US government AI testing underway - Tech giants to evaluate models Scan TV
Google News AI Testing
Collate Emphasizes Semantic Data Layer as Key to Enterprise AI Reliability TipRanks
METR Blog
External review from METR of the "Risks from automated R&D" section in Anthropic's February 2026 Risk Report
METR Blog
We distinguish three measures of AI uplift -- on old tasks, on new tasks, and in value -- and show that task substitution can cause these to diverge substantially.
Google News AI Testing
Tech giants agree to US government AI testing programme Euronews.com
Google News SWE Bench
Scale Labs debuts new Refactoring Leaderboard for AI TestingCatalog AI News
Google News MLPerf
Cisco and AMD Benchmark Scale-out AI Fabric Performance Let's Data Science
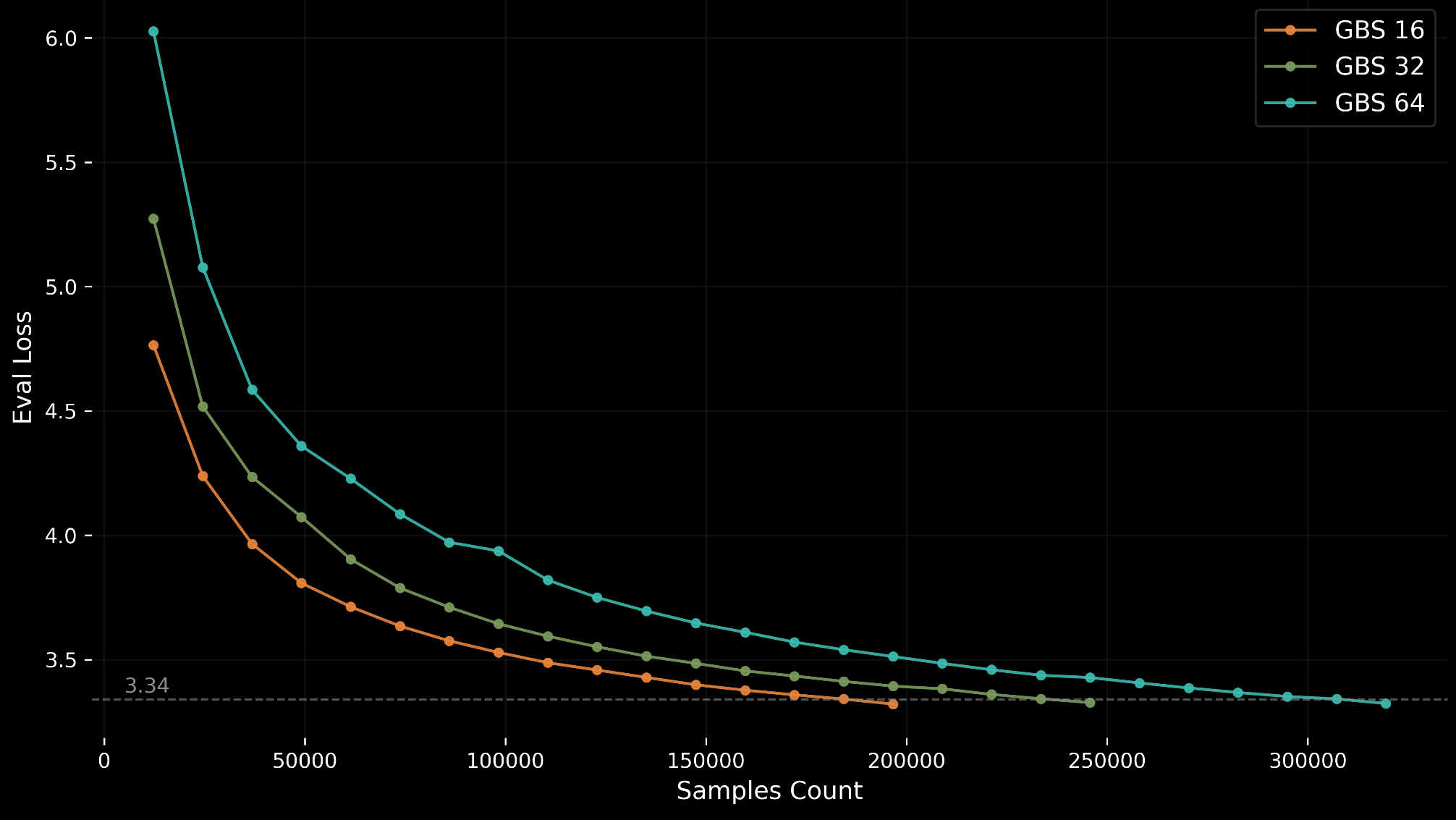
MLCommons Evaluation Filter
MLPerf Training v6.0 introduces GPT-OSS 20B, a new sparse Mixture-of-Experts (MoE) pretraining benchmark designed for accessibility on single 8-GPU nodes.
Google News AI Benchmarks
+ 1 source
DeepSeek V4 analysis: What's the point of topping the AI leaderboard if nobody can afford you? news.cgtn.com
Google News AI Testing
How to Engineer AI Reliability: A 5-Step Framework for Founders Substack
Google News AI Testing
New framework evaluates AI reliability in immune system prediction Drug Target Review
More stories load automatically as you scroll.